事件脈絡與異常分析
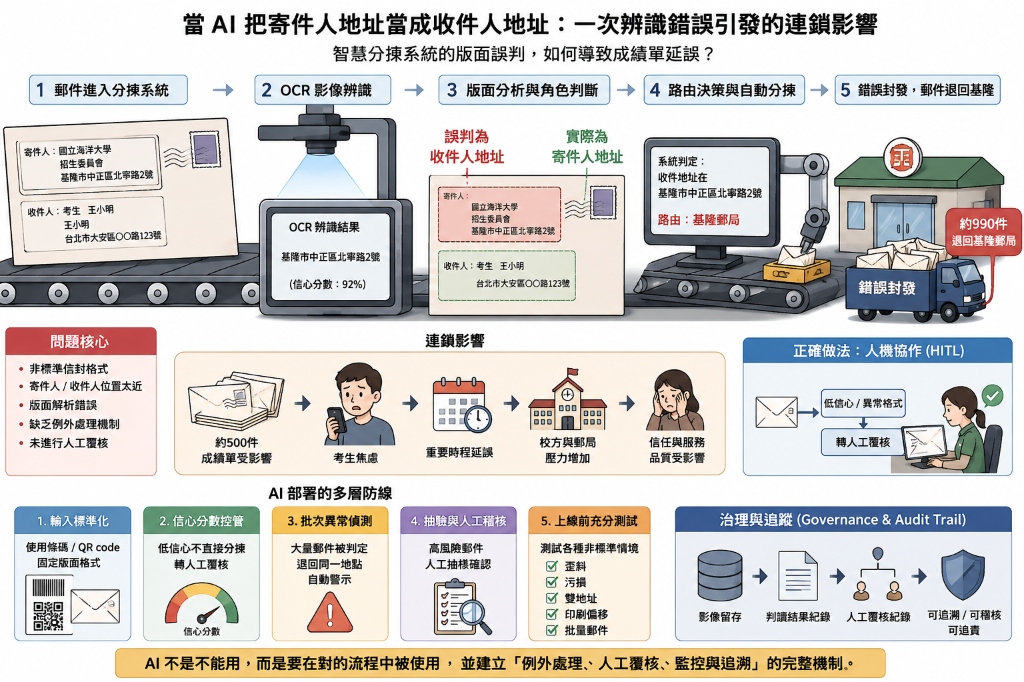
台北郵局在導入自動化分揀系統後,因 OCR 自動辨識誤判,將海洋大學交寄的 1773 件考生成績單中的部分郵件,誤將「寄件人地址」當作「收件人地址」,導致約 500 件郵件被錯誤分揀並退回起寄地基隆,造成嚴重的投遞延誤。
原始新聞來源與重點摘要
新聞網址:自由時報 - 海大甄選成績單延誤 中華郵政出面道歉:調整機器分揀辨識
- 事件起因:海洋大學於 2026/5/29 委託寄發 1,773 件考生成績單大宗普通掛號郵件,因信封上寄、收件人地址皆偏向中間印製,屬於「非標準格式」。
- 系統誤判:郵件於台北郵件處理中心(A7 智慧物流園區)分揀時,機器 OCR 誤將「寄件人地址(海大)」判讀為收件人,導致約 990 件郵件被錯誤退回基隆(其中約 500 件為成績單),引發投遞延誤。
- 緊急應變:中華郵政發現後增加投遞頻率,並取得校方諒解,配合提供資料供考生線上查詢或親自領取,於 6/5 晚間前全數完成投遞,未影響考生權益。
- 技術檢討:掛號郵件的機器分揀比例從以往的 20% 提升至 70%,但對非標準信封的容錯率不足。後續將調整機器辨識設定,並要求廠商增設「非標準書寫排除機制」,若遇非標郵件則改用人工分揀。
Step 1 大宗普通掛號寄件 (收寄件人資訊皆偏中間,符合以往人工習慣)
Step 2 進入 A7 智慧物流自動分揀 (掛號機器處理比率從 20% 激增至 70%)
→
Step 3 機器 OCR 缺乏例外判定邏輯,強行將「寄件人資訊」辨識為收件人
→
最離譜的痛點:發生在資源最充足的台北首都門戶
這次的系統性辨識延誤,並非發生在偏遠地區,而是發生在國家投入最巨資、設施最現代化且剛啟用不久的台北郵件處理中心(台北首都門戶)。這證明了一個殘酷的現實:再先進的硬體、再龐大的預算投資,如果系統設計缺乏合理的知識工程(如邏輯校對 Audit 與 HITL 人機協作稽核),在面對真實世界的例外輸入時,依然會發生極為低級的系統癱瘓與業務故障。
OCR 辨識策略與自動化審核 (Audit)
- 非標分流與信賴度標記:系統必須具備辨識「異常格式」的能力。若輸入文件不符合標準格式(例如收寄件人地址重疊、字體位置異常),機器應標註低信賴度並主動路由至人工複核管道。
- 合理性交叉驗證 (Cross-Validation):系統在讀取到欄位資料後,應與後台的地理/業務資料庫比對。例如收件地址與寄件地址完全一致,邏輯上即屬矛盾,系統應在自動分揀完成前自動攔截。
HITL (Human-in-the-Loop) 的必要性
雖然自動化分揀能使每小時處理量從 6,000 件提升至 24,000 件,但缺乏人機協作機制 (HITL) 的把關,會導致低級錯誤大規模擴展。
| 辨識模式 | 優點 | 缺點與風險 | 改善對策 |
|---|---|---|---|
| 完全自動化 (No HITL) | 處理速度極快,節省大量人工成本。 | 機器遇到例外或特殊排版時,容易盲目誤判並執行,造成群體性錯誤。 | 增設邊界排除與低信賴度排除邏輯。 |
| 人機協作 (HITL) | 兼具機器的速度與人類的邏輯判斷,容錯率與精準度極高。 | 遇到異常件較多時,人工複核會產生微小的處理瓶頸。 | 優化 AI 預處理,僅將低信賴度或特殊件分流至人工介面複核。 |
在銀河 ERP 自動化系統中的實務應用
銀河 ERP 系統的 AI 自動化模組在處理財務憑證與單據時,亦面臨相同的邊界問題,必須採取以下人機協作策略:
- 電子發票 AI OCR 審核:AI 可讀取掃描發票並自動抓取統編、金額與品項。然而,系統必須設計財務會計審核介面(HITL),讓會計人員能在過帳付款前進行最終確認,防範機器將廣告文案或發票統編誤認為交易金額。
- 生產派程合理性稽核:AI 自動生成排程單後,必須通過生產線組長的人工一鍵審查(HITL),以應對即時突發的設備故障或物料臨時變動。